Last updated on June 30th, 2024 at 03:21 pm
Table of Contents
Right Hand Assignments
Normally, when you assign a value to a variable, you have the variable being assigned to on the left and the value assigned on the right, such as:
my_variable = 12Ruby also allows the reverse with the Right Hand Assignment operator.
12 => my_variableWhere would this be helpful? Well, lets say that you want to assign values from a hash. Assuming a hash like:
person = {name: {first: "Bob", last: "Roberts"}}values would normally be extracted with something like:
first_name = person[:name][:first]
last_name = person[:name][:last]It can be made more “elegant” with:
person => { name: { first: , last: } }
puts first
puts lastJust for clarification – running the example above in irb generates the warning “warning: One-line pattern matching is experimental, and the behavior may change in future versions of Ruby!“. This warning is related to the usage of the pattern matching for the assignment, not for the right hand assignment.
Closures, kinda
In Ruby, a Closure is defined as a code block that can be passed to methods and executed, referring to variables from the context in which it was created. A closure in Ruby is, more or less, code that is contained within a pair of curly braces, {…}, or begin and end statements.
Blocks
Every programmer is familiar with the concept of defining methods and calling them with parameters. In most cases parameters are objects, such as strings, numbers, etc. Because everything in Ruby is an object, including code blocks, you can pass code blocks to methods and have them executed. Let’s have a quick look….
def method_1
yield
end
method_1 {puts "Print this string"}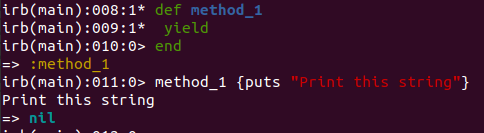
You will quickly notice that although we didn’t define any parameters with the method, the yield statement executed the passed block. The block was passed implicitly. Just for grins, let’s have a look and see what happens if we execute the yield twice in the method.
def method_1
yield
yield
end
method_1 {puts "Print this string"}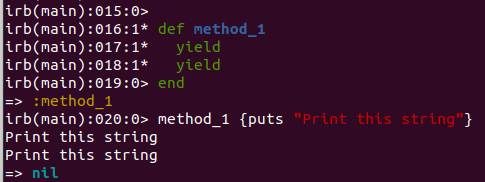
It is no great surprise to see that the same block was executed at the second yield statement. Now let’s experiment some more and add a variable to the mixture.
def method_1
a = 12
yield
a = 99
yield
end
method_1 {puts "a has the value #{a}"}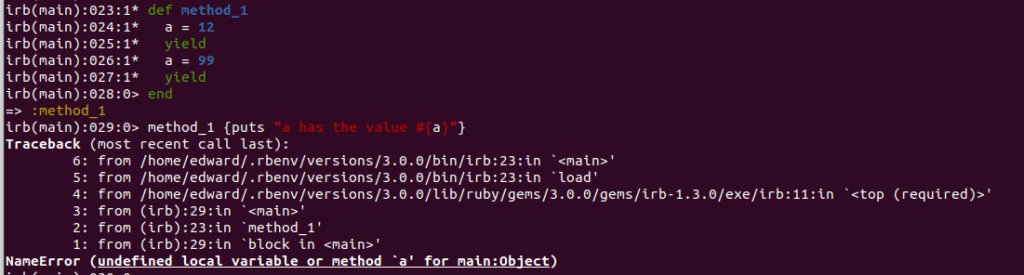
This time we get an error message even though the variable ‘a’ was defined in the method. To pass parameters to the block, you have to use the same process that we are familiar with from the each and map methods, which is to define the variable as a parameter to the block.
def method_1
yield 12
yield 99
end
method_1 { |i| puts "We have the value #{i}"}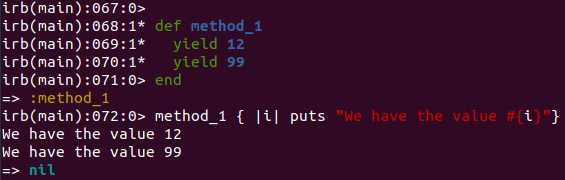
You can also define the block explicitly in the method definition, as well as check to see if it exists. Also, instead of yield, you can use the call method.
def method_1 &block
if block_given?
block.call 12
end
end
method_1 { |i| puts "We have the value #{i}"}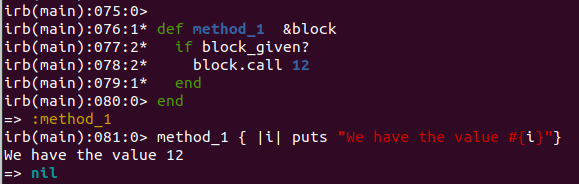
Procs
Ruby also has the ability to store a block of code in a Proc. This can be passed to methods and invoked similar to a block. While only a single block can be passed as an argument to a method, any number of procs can be passed to a method.
proc_1 = Proc.new { |i| puts "We have the value #{i}"}
def method_1 proc
proc.call 12
end
method_1 proc_1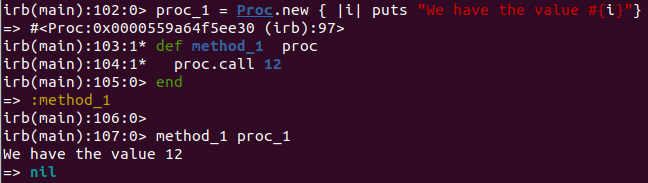
Did you notice that when we passed a block explicitly, we prefixed the name of the block with a ampersand ‘&’? This is will tell Ruby to automatically take the passed block and turn it into a Proc. What’s the difference between a Proc and a Block? From what I understand, the only meaningful difference is that the Proc has better performance than a Block.
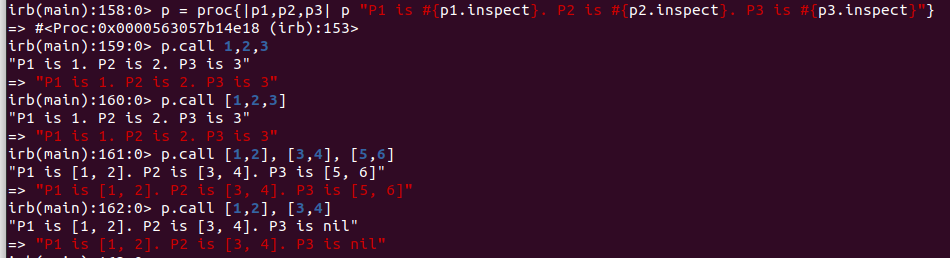
There is also an option to calling a Proc. Instead of using the call method, you can pass the parameters as an array.
p = proc{|p1,p2,p3| p "P1 is #{p1.inspect}. P2 is #{p2.inspect}. P3 is #{p3.inspect}"}
p.call 1,2,3
p[1,2,3]
Lambdas
Ruby also has the concept of a Lambda, which is similar to a block and Proc, but not exactly the same. What I find interesting is that when you define a Lambda, irb will tell you that you have actually defined a Proc, with a “(lambda)” characteristic (?) at the end. If you pull the class name from the Lambda, it will say that it is a Proc.
lambda_1 = lambda { |i| puts "We have the value #{i}"}
def method_1 l_1
l_1.call 12
end
method_1 lambda_1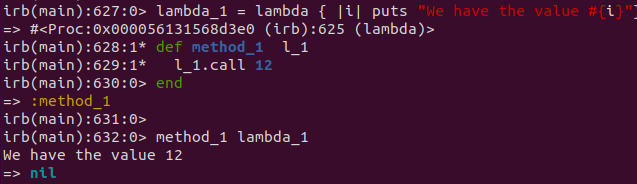
There are a variety of ways to declare a Lambda. You can use the lambda keyword, as well as the shortcut “->”.
lambda_1 = -> {puts "This is a lambda"}
lambda_1.call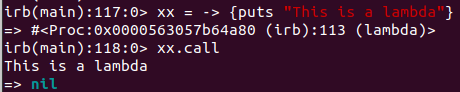
You can also specify parameters for the Lambda.
lambda_1 = -> (param1) {puts "This is a lambda with the parameter #{param1}"}
lambda_1.call(12)
The key difference between Lambdas and Blocks / Procs, is that a return statement will not only immediately terminate the Block / Proc, but also the method calling it. A Lambda, on the other hand, will behave more like a method and return control to the calling method.
Additionally, if you declare a Proc, it doesn’t pay as much attention to the number of arguments passed to it as a Lambda does. A Lambda will give you an error messages if you pass more arguments than the Lambda defines, whereas a Proc will simply ignore the additional arguments. As well, a Proc will expand an array without the splat (*) instruction, if the number of arguments is below the expected count and the number of objects in the array is the same as the number of arguments expected.
To better understand the differences between Blocks, Procs and Lambdas, please have a look at an excellent explanation by Paul Cantrell
at_exit
Whenever you exit a Ruby program, it will return a status to the operating system to indicate whether or not the program’s execution was successful. You can modify this behavior, if you wish, to change the exit status or even provide explanatory text messages. I suggest you have a look at the interesting post that Starr Horne has written to clarify things.